Appendix E — Authoritative table of explanatory variables on the Output Area level
This notebook creates an authoritative table of explanatory variables on the output area level. It joins or interpolates data of indicators and explanatory variables to create a single GeoDataFrame that will eventually be used for modelling.
import geopandas as gpdimport toblerimport pandas as pdimport numpy as npimport poochimport urbangrammar_graphics as ugg
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_10962/2464167658.py:1: UserWarning: Shapely 2.0 is installed, but because PyGEOS is also installed, GeoPandas will still use PyGEOS by default for now. To force to use and test Shapely 2.0, you have to set the environment variable USE_PYGEOS=0. You can do this before starting the Python process, or in your code before importing geopandas:
import os
os.environ['USE_PYGEOS'] = '0'
import geopandas
In a future release, GeoPandas will switch to using Shapely by default. If you are using PyGEOS directly (calling PyGEOS functions on geometries from GeoPandas), this will then stop working and you are encouraged to migrate from PyGEOS to Shapely 2.0 (https://shapely.readthedocs.io/en/latest/migration_pygeos.html).
import geopandas as gpd
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/shapely/set_operations.py:133: RuntimeWarning: invalid value encountered in intersection
return lib.intersection(a, b, **kwargs)
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: aqi, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
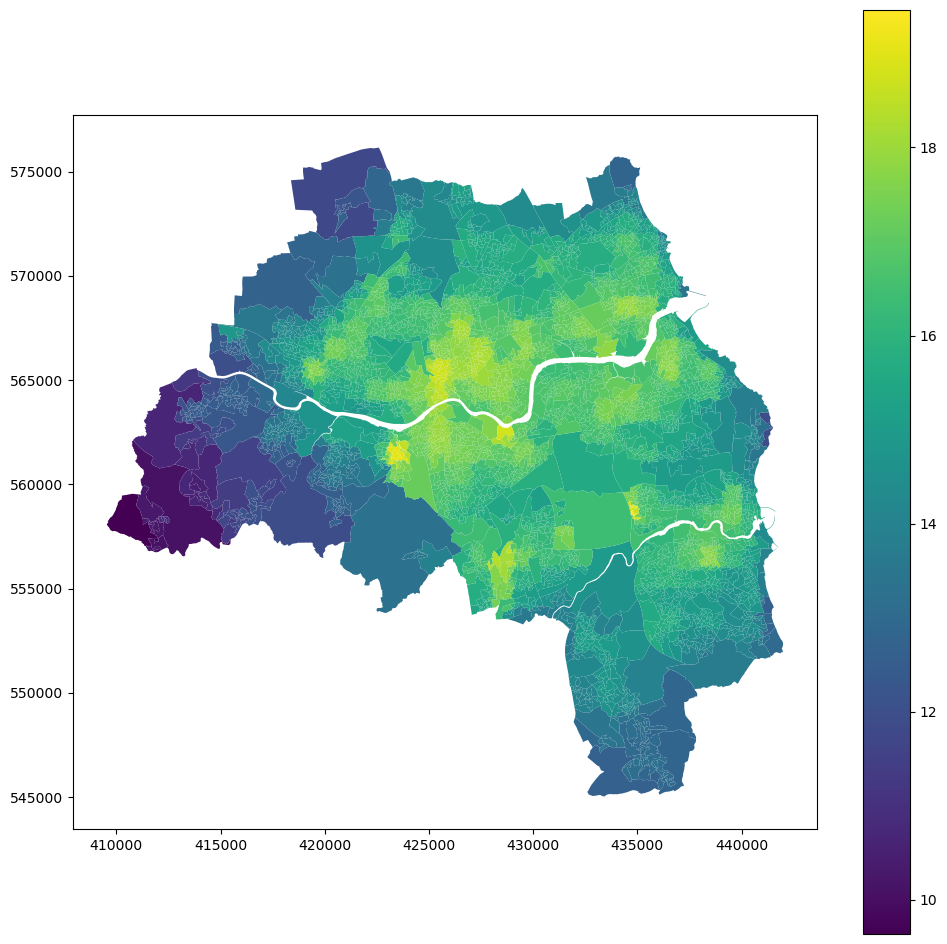
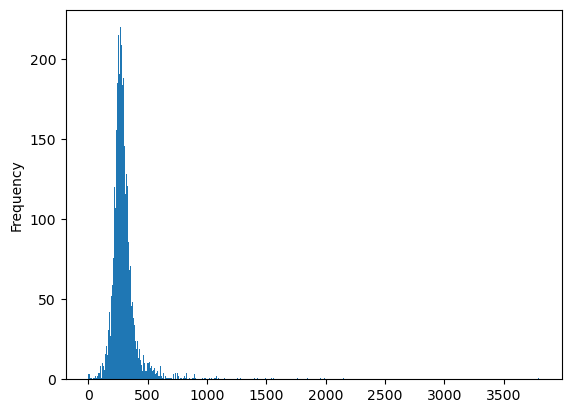
Visual check.
interp.plot("aqi", figsize=(12, 12), legend=True)
Assign the interpolated values to the OA dataframe.
oa_aoi["air_quality_index"] = interp.aqi.values
E.2 House prices
House prices are reported on the OA level and can be merged via attribute.
Question: We need to figure out what to do with OAs that do not have any house price data. I would probably drop them before the training of ML. Interpolation may be tricky as we don’t know the exact reasons for their missingness (may be mostly parks…). We can also try to load older data there but given the dynamics of house pricing, that may cause more trouble than good.
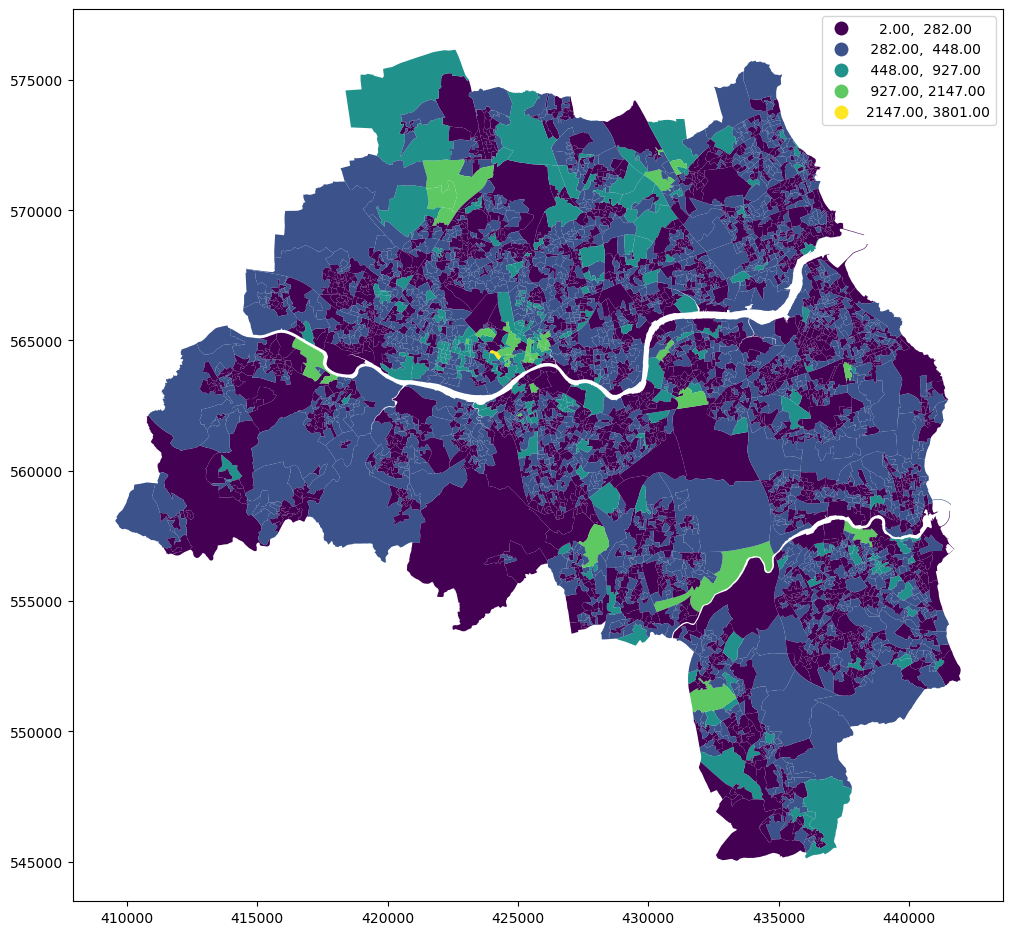
E.2.1 Job Accessibility
Job accessibility is measured on the OA level and can be merged.
jobs = pd.read_csv(f"{data_folder}/outputs/results_accessibility/acc_jobs15_OAtoWPZ_tynewear.csv", index_col=0,)jobs.head()
wp_interpolated = tobler.area_weighted.area_interpolate( wp_tyne, oa_aoi, extensive_variables=["A, B, D, E. Agriculture, energy and water","C. Manufacturing","F. Construction","G, I. Distribution, hotels and restaurants","H, J. Transport and communication","K, L, M, N. Financial, real estate, professional and administrative activities","O,P,Q. Public administration, education and health","R, S, T, U. Other", ],)
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/shapely/set_operations.py:133: RuntimeWarning: invalid value encountered in intersection
return lib.intersection(a, b, **kwargs)
And assign the result to OA dataframe.
oa_aoi[ ["A, B, D, E. Agriculture, energy and water","C. Manufacturing","F. Construction","G, I. Distribution, hotels and restaurants","H, J. Transport and communication","K, L, M, N. Financial, real estate, professional and administrative activities","O,P,Q. Public administration, education and health","R, S, T, U. Other", ]] = wp_interpolated.drop(columns="geometry").values
E.3.3 Land cover (CORINE)
CORINE is shipped as custom polygons. We use the data downloaded for the Urban Grammar project.
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/shapely/set_operations.py:133: RuntimeWarning: invalid value encountered in intersection
return lib.intersection(a, b, **kwargs)
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: sdbAre, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: sdbPer, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: sdbCoA, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbCCo, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbCor, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbSqu, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbERI, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbElo, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbCCM, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: ssbCCD, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: stbOri, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: sicCAR, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: stbCeA, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: mtbAli, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: mtbNDi, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: stbSAl, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/tobler/util/util.py:32: UserWarning: nan values in variable: lieWCe, replacing with 0
warn(f"nan values in variable: {column}, replacing with 0")
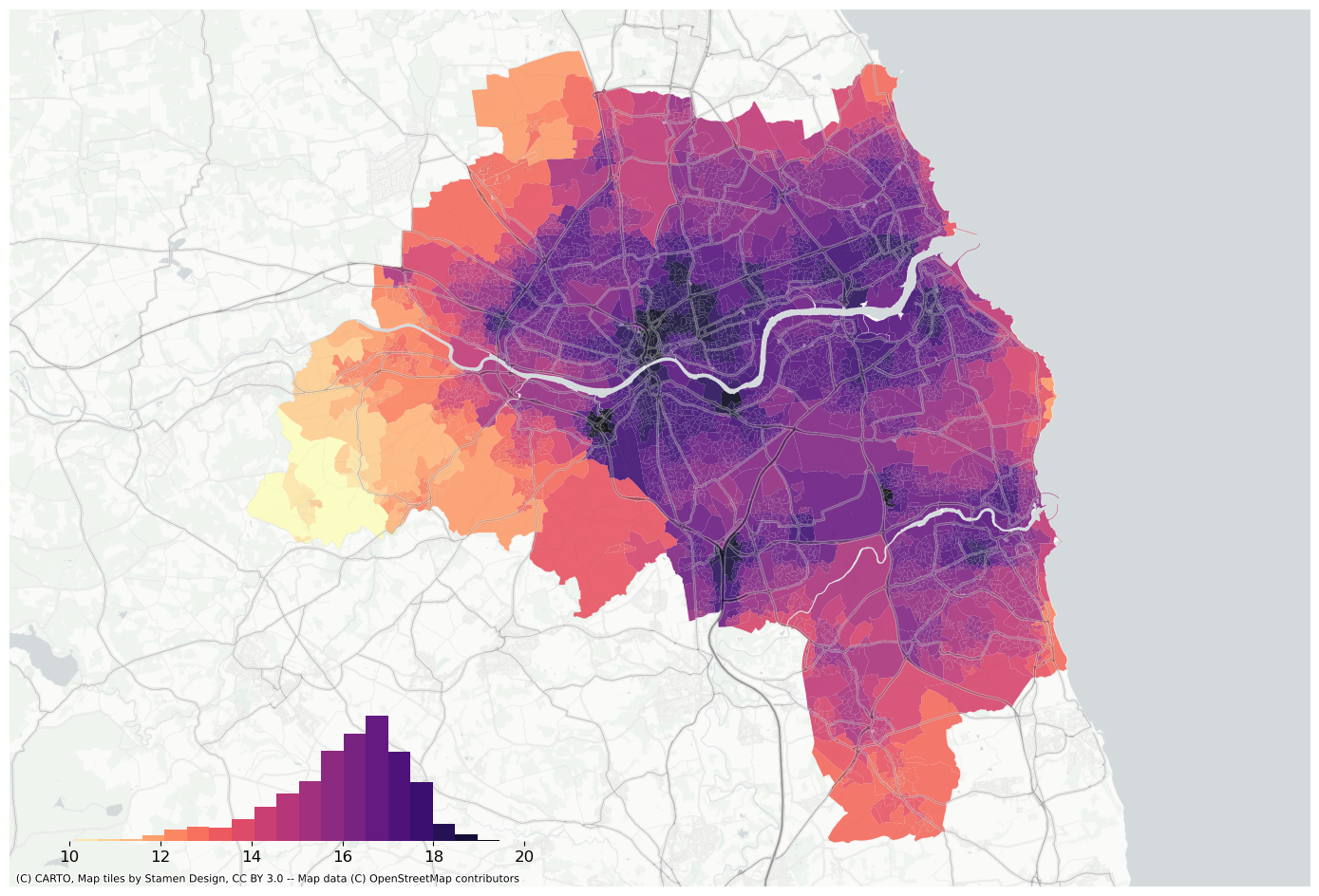
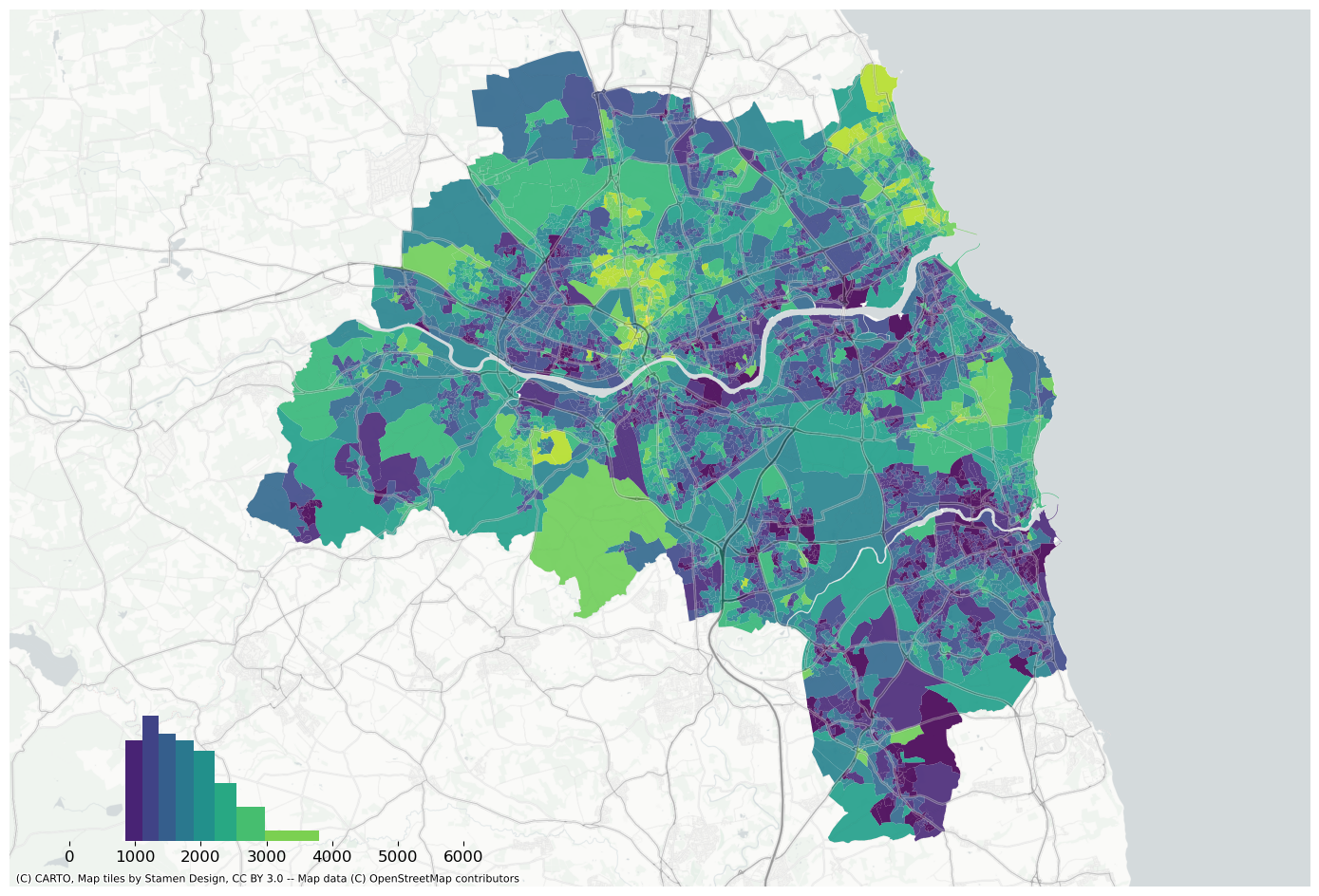
f, ax = plt.subplots(figsize=(18, 12))extent.plot(ax=ax, alpha=0)oa_aoi.to_crs(3857).plot("air_quality_index", scheme="equalinterval", k=20, ax=ax, alpha=0.9, cmap="magma_r")bins = mapclassify.EqualInterval(oa_aoi["air_quality_index"].values, k=20).binslegendgram( f, ax, oa_aoi["air_quality_index"], bins, pal=palmpl.Magma_20_r, legend_size=(0.35, 0.15), # legend size in fractions of the axis loc="lower left", # matplotlib-style legend locations clip=(10, 20), # clip the displayed range of the histogram)ax.set_axis_off()contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels.build_url(scale_factor="@2x"), attribution="",)contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors",)# plt.savefig(f"{data_folder}/outputs/figures/air_quality_index.png", dpi=150, bbox_inches="tight")plt.savefig(f"{data_folder}/outputs/figures/svg/air_quality_index.svg", dpi=144, bbox_inches="tight",)
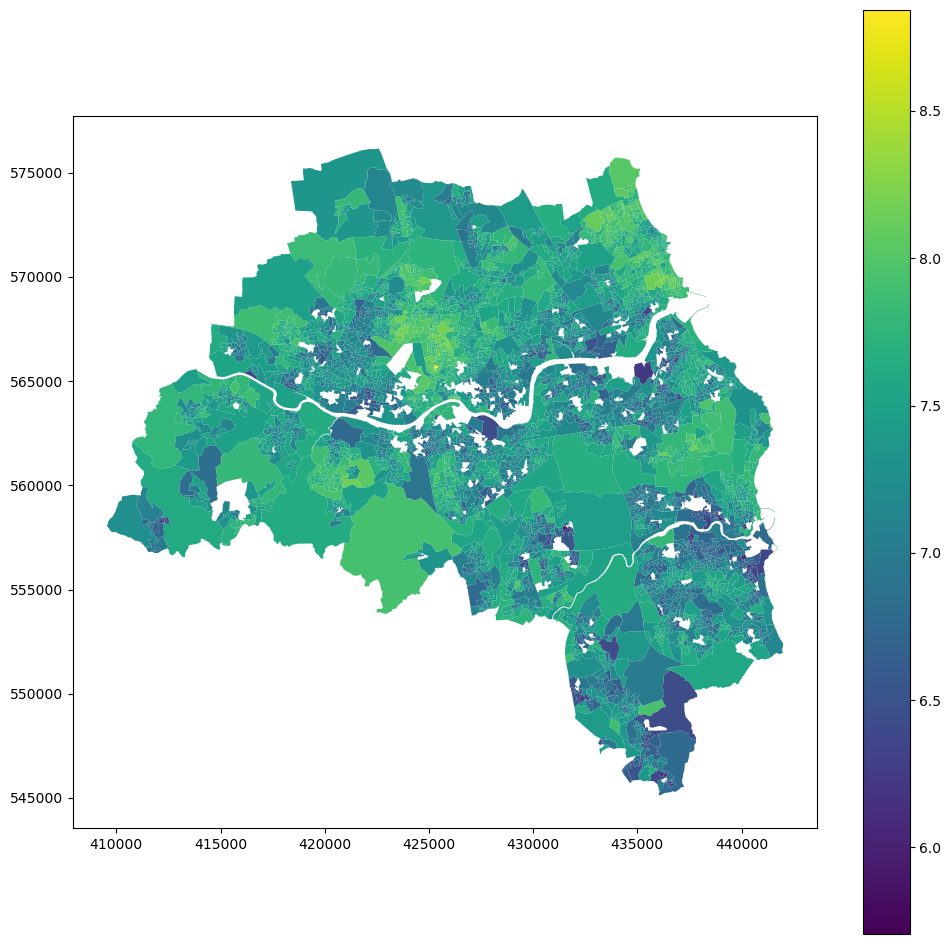
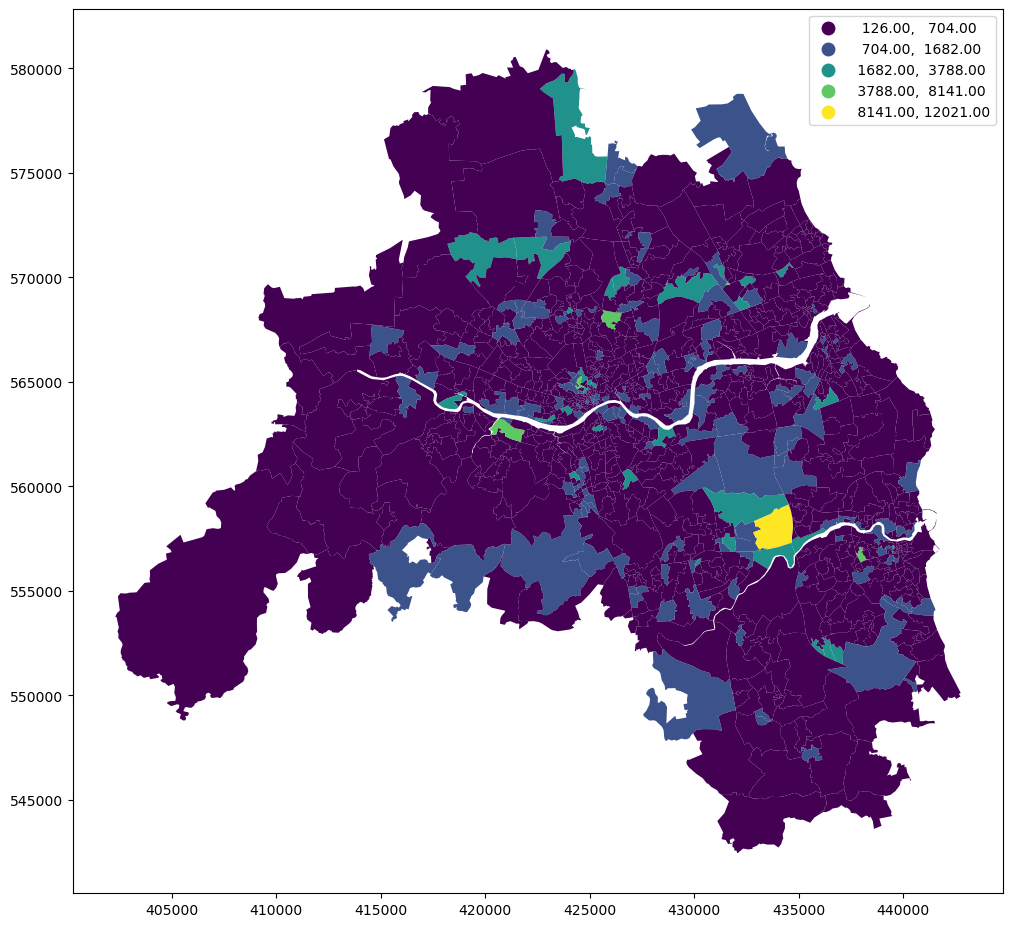
E.4.0.2 House price
Filling NAs just for plotting purposes.
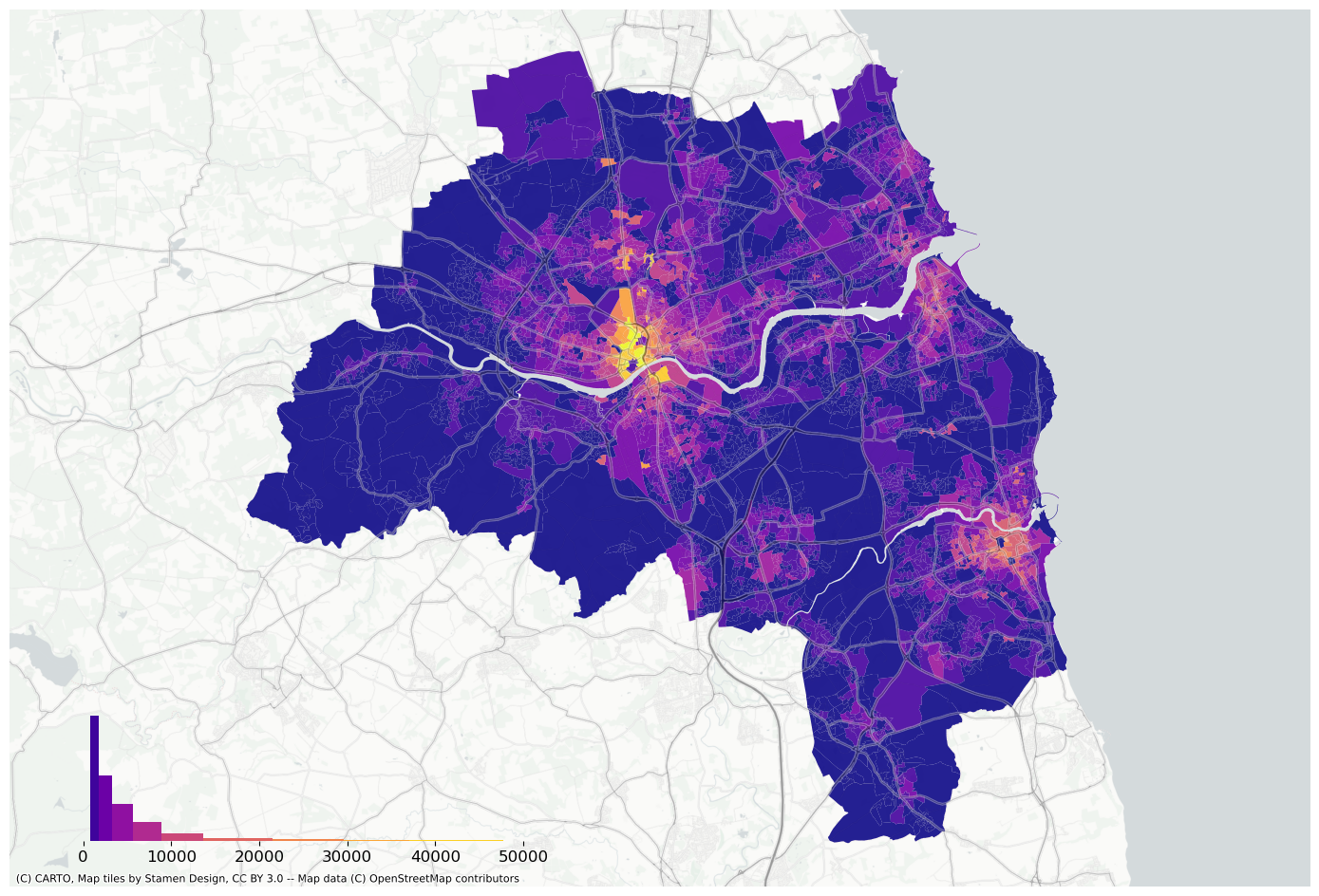
f, ax = plt.subplots(figsize=(18, 12))extent.plot(ax=ax, alpha=0)oa_aoi.to_crs(3857).plot( oa_aoi["house_price_index"].fillna(method="pad"), scheme="naturalbreaks", k=10, ax=ax, alpha=0.9, cmap="viridis",)bins = mapclassify.NaturalBreaks(oa_aoi["house_price_index"].dropna().values, k=10).binslegendgram( f, ax, oa_aoi["house_price_index"].dropna(), bins, pal=palmpl.Viridis_10, legend_size=(0.35, 0.15), # legend size in fractions of the axis loc="lower left", # matplotlib-style legend locations clip=(0, oa_aoi["house_price_index"].max(), ), # clip the displayed range of the histogram)ax.set_axis_off()contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels.build_url(scale_factor="@2x"), attribution="",)contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors",)# plt.savefig(f"{data_folder}/outputs/figures/house_price_index.png", dpi=150, bbox_inches="tight")plt.savefig(f"{data_folder}/outputs/figures/svg/house_price_index.svg", dpi=144, bbox_inches="tight",)
E.4.0.3 Jobs accessibility
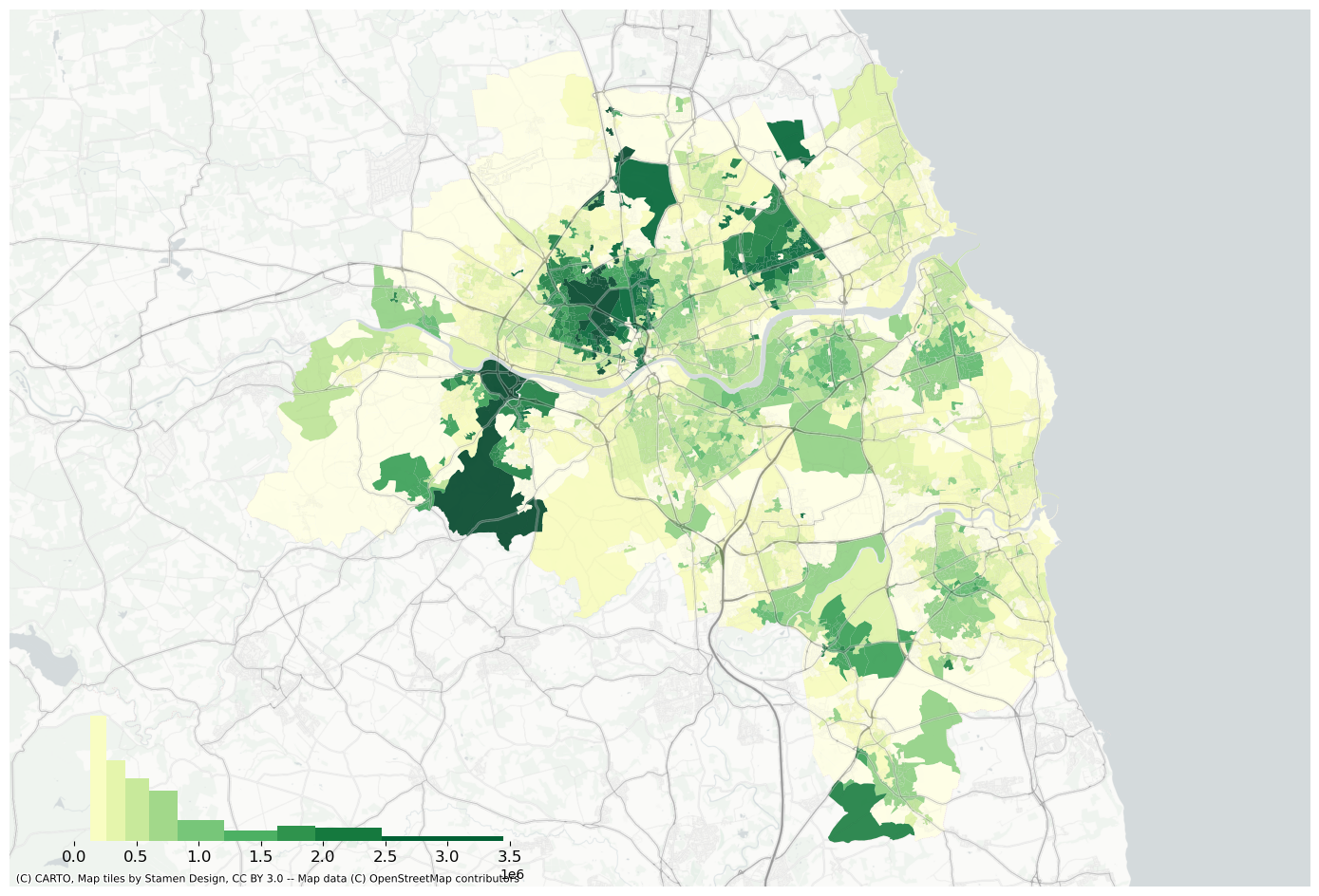
f, ax = plt.subplots(figsize=(18, 12))extent.plot(ax=ax, alpha=0)oa_aoi.to_crs(3857).plot( oa_aoi["jobs_accessibility_index"].fillna(method="pad"), scheme="naturalbreaks", k=10, ax=ax, alpha=0.9, cmap="plasma",)bins = mapclassify.NaturalBreaks( oa_aoi["jobs_accessibility_index"].dropna().values, k=10).binslegendgram( f, ax, oa_aoi["jobs_accessibility_index"].dropna(), bins, pal=palmpl.Plasma_10, legend_size=(0.35, 0.15), # legend size in fractions of the axis loc="lower left", # matplotlib-style legend locations# clip = (10,20), # clip the displayed range of the histogram)ax.set_axis_off()contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels.build_url(scale_factor="@2x"), attribution="",)contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors",)# plt.savefig(f"{data_folder}/outputs/figures/jobs_accessibility_index.png", dpi=150, bbox_inches="tight")plt.savefig(f"{data_folder}/outputs/figures/svg/jobs_accessibility_index.svg", dpi=144, bbox_inches="tight",)
f, ax = plt.subplots(figsize=(18, 12))extent.plot(ax=ax, alpha=0)oa_aoi.to_crs(3857).plot( oa_aoi["greenspace_accessibility_index"].fillna(method="pad"), scheme="naturalbreaks", k=10, ax=ax, alpha=0.9, cmap="YlGn",)bins = mapclassify.NaturalBreaks( oa_aoi["greenspace_accessibility_index"].dropna().values, k=10).binslegendgram( f, ax, oa_aoi["greenspace_accessibility_index"].dropna(), bins, pal=matplotlib.cm.get_cmap("YlGn"), legend_size=(0.35, 0.15), # legend size in fractions of the axis loc="lower left", # matplotlib-style legend locations# clip = (10,20), # clip the displayed range of the histogram)ax.set_axis_off()contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels.build_url(scale_factor="@2x"), attribution="",)contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors",)# plt.savefig(f"{data_folder}/outputs/figures/greenspace_accessibility_index.png", dpi=150, bbox_inches="tight")plt.savefig(f"{data_folder}/outputs/figures/svg/greenspace_accessibility_index.svg", dpi=144, bbox_inches="tight",)
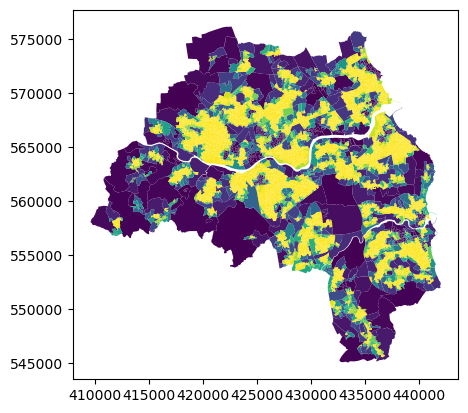
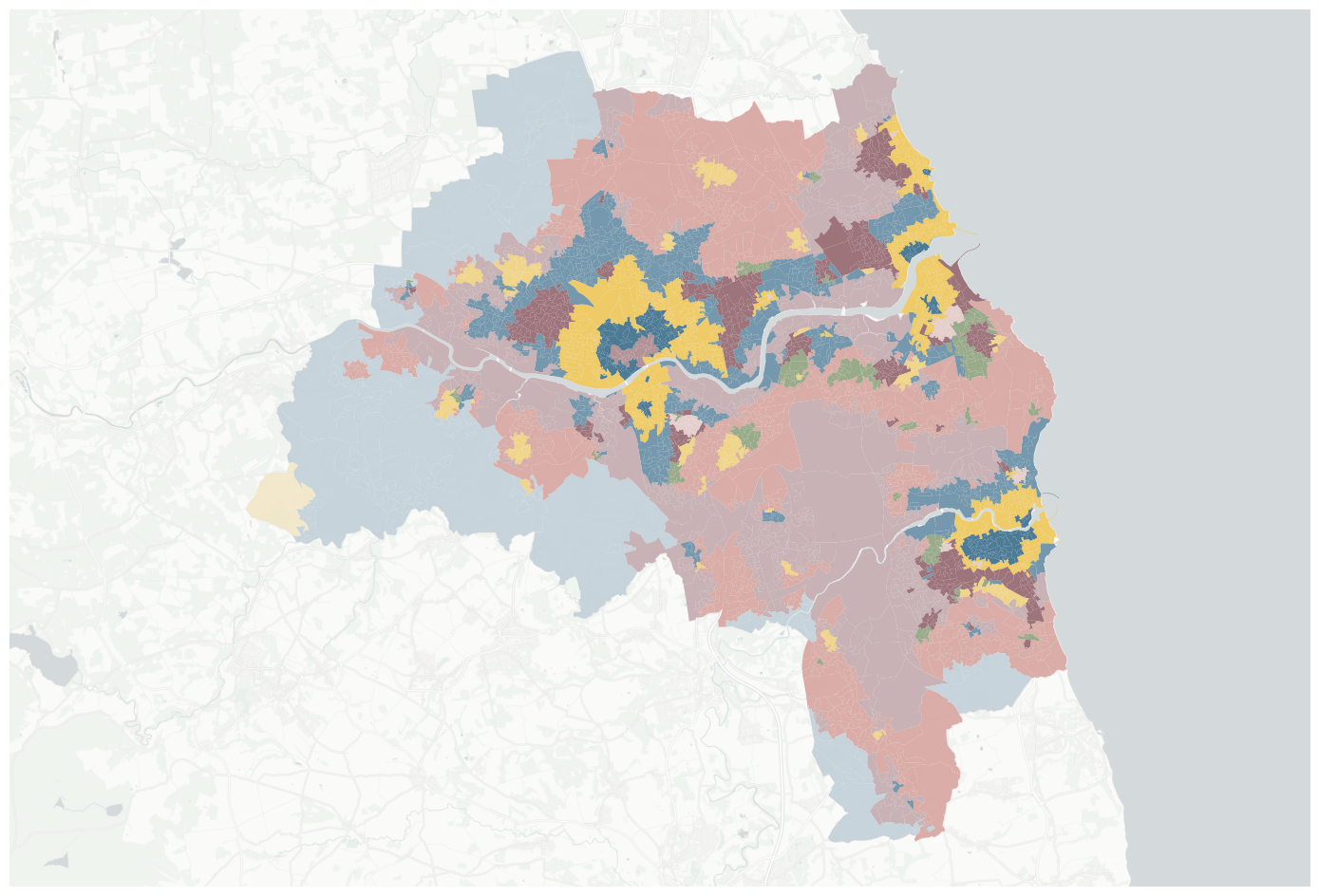
E.4.0.4 Explanatory variables
Some explanatory variables are better to be plotted as densities.
to_density = ["A, B, D, E. Agriculture, energy and water","C. Manufacturing","F. Construction","G, I. Distribution, hotels and restaurants","H, J. Transport and communication","K, L, M, N. Financial, real estate, professional and administrative activities","O,P,Q. Public administration, education and health","R, S, T, U. Other","population_estimate",]
Loop over explanatory variables, assign a random hue, generate a colormap and plot.
for char in oa_aoi.columns.drop( ["geometry","geo_code","air_quality_index","house_price_index","jobs_accessibility_index", ]):if char in to_density: values = oa_aoi[char] / oa_aoi.areaelse: values = oa_aoi[char] gdf = oa_aoi.to_crs(3857) hue = np.random.randint(0, 360, 1)[0] k =10# number of classes clip =None# clip=(0, 100) # in case of long tail mc = mapclassify.NaturalBreaks(values, k=k).bins # classification scheme bins =50# resolution of histogram# plotting color = (hue, 75, 35) c = husl.husl_to_hex(*color) cmap = sns.light_palette(color, input="husl", as_cmap=True, n_colors=k) ax = gdf.plot( values, cmap=cmap, figsize=(18, 12), scheme="UserDefined", k=k, classification_kwds=dict(bins=mc), ) extent.plot(ax=ax, alpha=0) ax.set_axis_off()# add legend hax = legendgram( plt.gcf(), # grab the figure, we need it ax, # the axis to add the legend values, # the attribute to map mc, cmap, # the palette to use legend_size=(0.35, 0.15), loc=4,# tick_params={'color':c, 'labelcolor':c,'labelsize':10}, clip=clip, bins=bins, ) # when usign legendgram, dev version from mpl_cmap branch should be used contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels, attribution="" ) contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors", ) plt.savefig(f"{data_folder}/outputs/figures/svg/ex_var_{char}.svg", dpi=144, bbox_inches="tight", ) plt.close()