Appendix L — House Price prediction model exploration
Development of a scikit-learn model able to predict the house price indicator from the explanatory variable capturing different scenarios.
import geopandas as gpdimport numpy as npimport pandas as pdimport contextilyimport palettable.matplotlib as palmplimport matplotlib.pyplot as pltimport mapclassifyimport libpysalfrom utils import legendgramfrom sklearn.ensemble import HistGradientBoostingRegressorfrom sklearn.metrics import mean_squared_errorfrom sklearn.model_selection import cross_val_predict, GridSearchCV
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_6968/881383173.py:1: UserWarning: Shapely 2.0 is installed, but because PyGEOS is also installed, GeoPandas will still use PyGEOS by default for now. To force to use and test Shapely 2.0, you have to set the environment variable USE_PYGEOS=0. You can do this before starting the Python process, or in your code before importing geopandas:
import os
os.environ['USE_PYGEOS'] = '0'
import geopandas
In a future release, GeoPandas will switch to using Shapely by default. If you are using PyGEOS directly (calling PyGEOS functions on geometries from GeoPandas), this will then stop working and you are encouraged to migrate from PyGEOS to Shapely 2.0 (https://shapely.readthedocs.io/en/latest/migration_pygeos.html).
import geopandas as gpd
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 3 disconnected components.
warnings.warn(message)
for col in exvars.columns.copy(): exvars[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(queen, exvars[col])
exvars.head()
population_estimate
A, B, D, E. Agriculture, energy and water
C. Manufacturing
F. Construction
G, I. Distribution, hotels and restaurants
H, J. Transport and communication
K, L, M, N. Financial, real estate, professional and administrative activities
O,P,Q. Public administration, education and health
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 3 disconnected components.
warnings.warn(message)
queen3.transform ="R"
for col in exvars.columns.copy(): exvars[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(queen3, exvars[col])
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
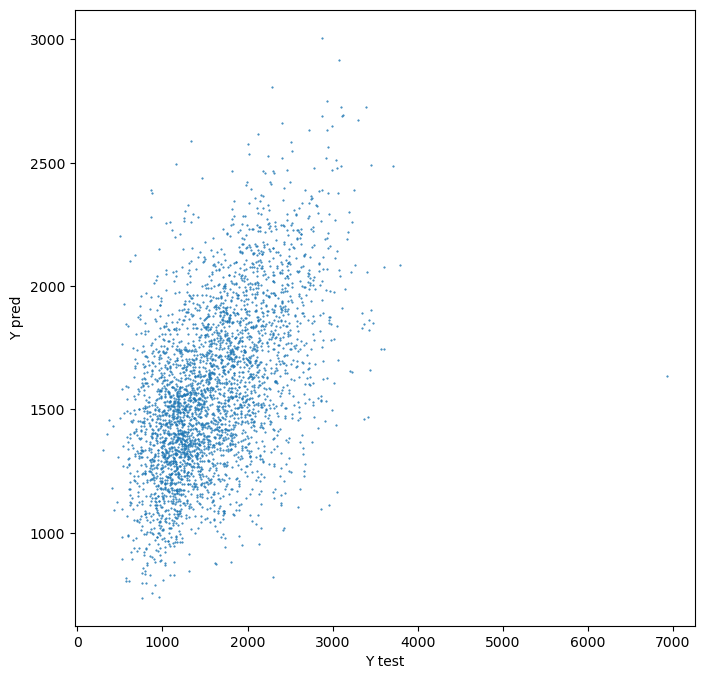
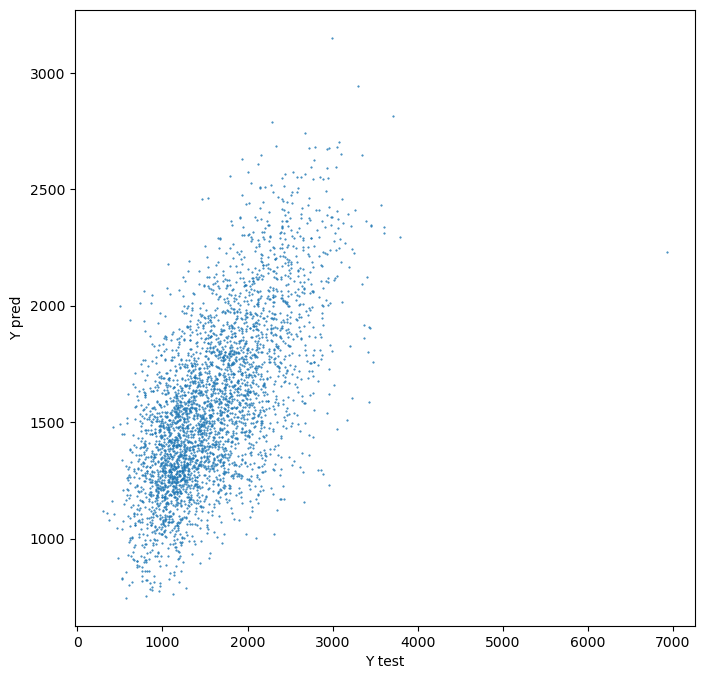
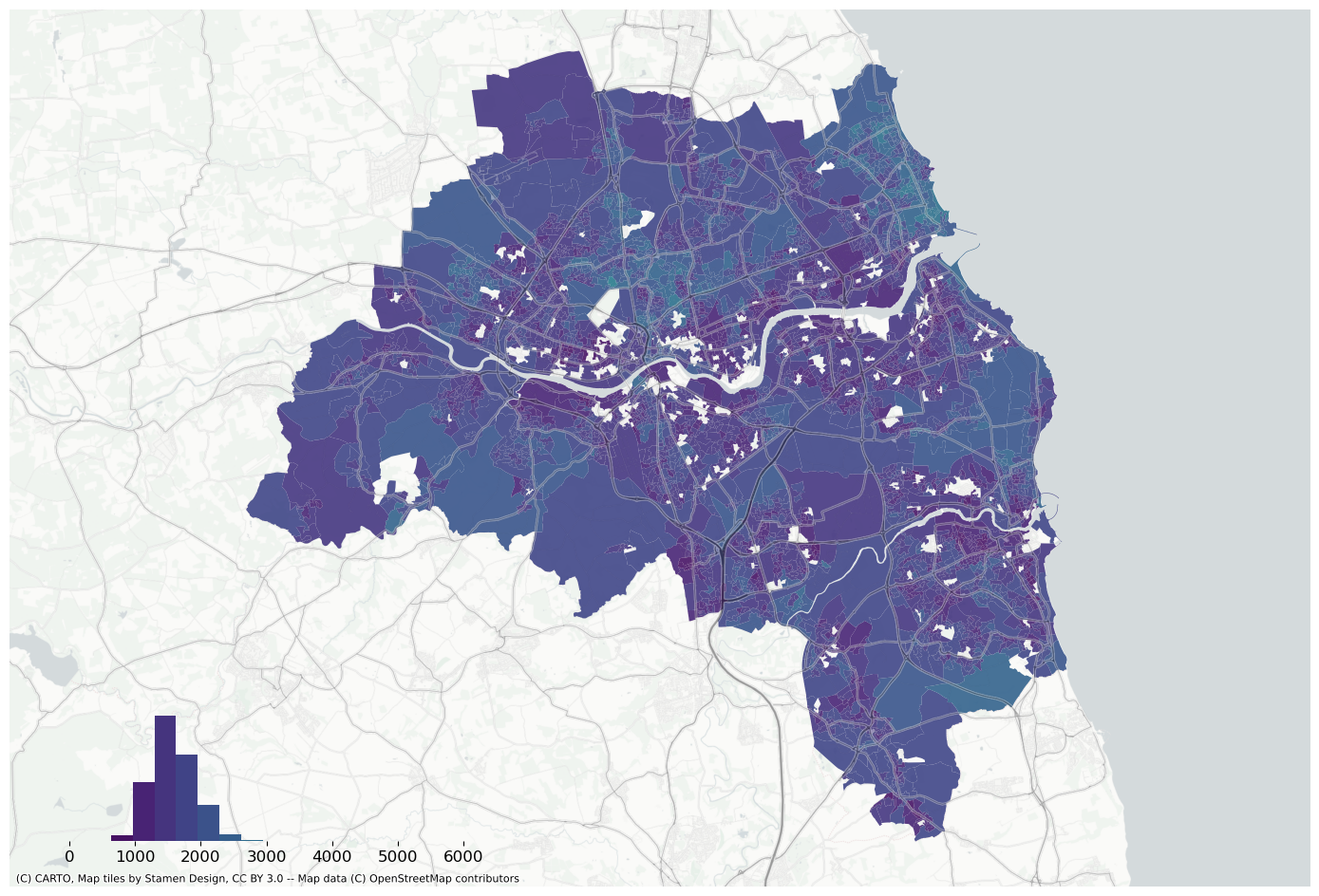
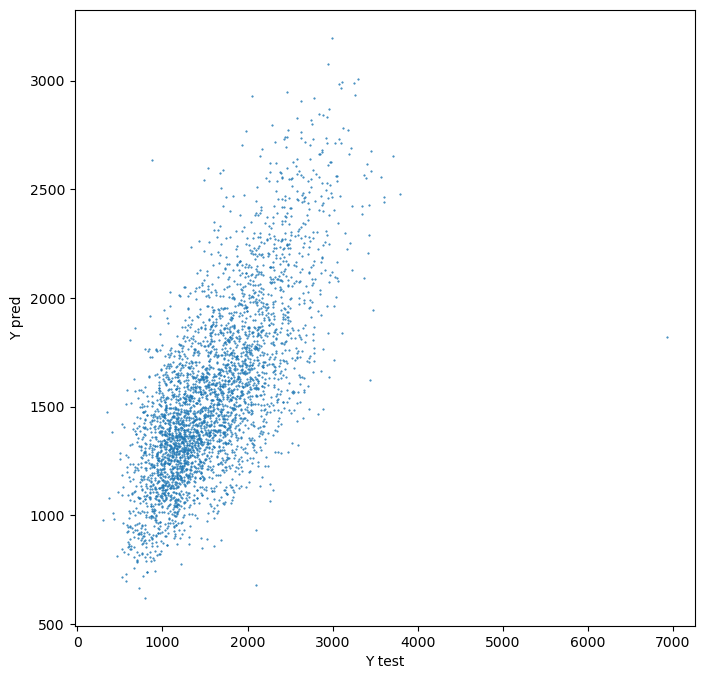
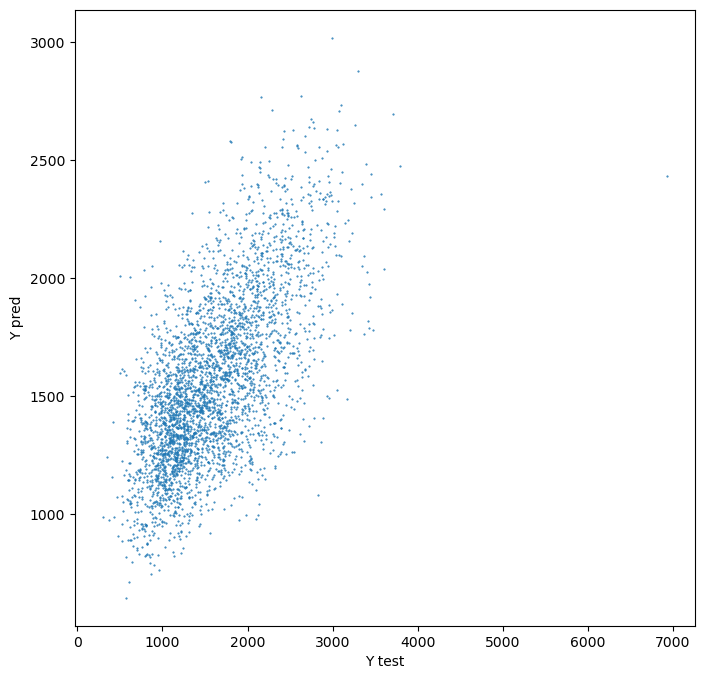
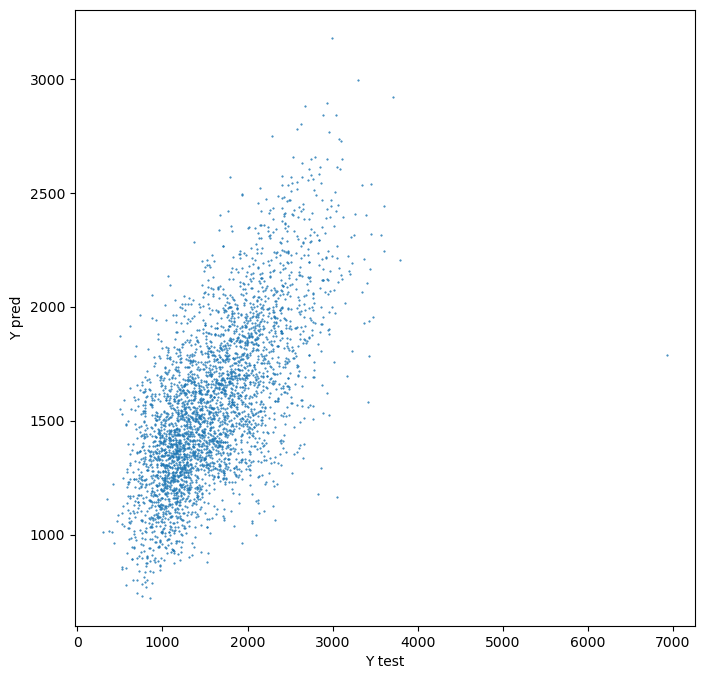
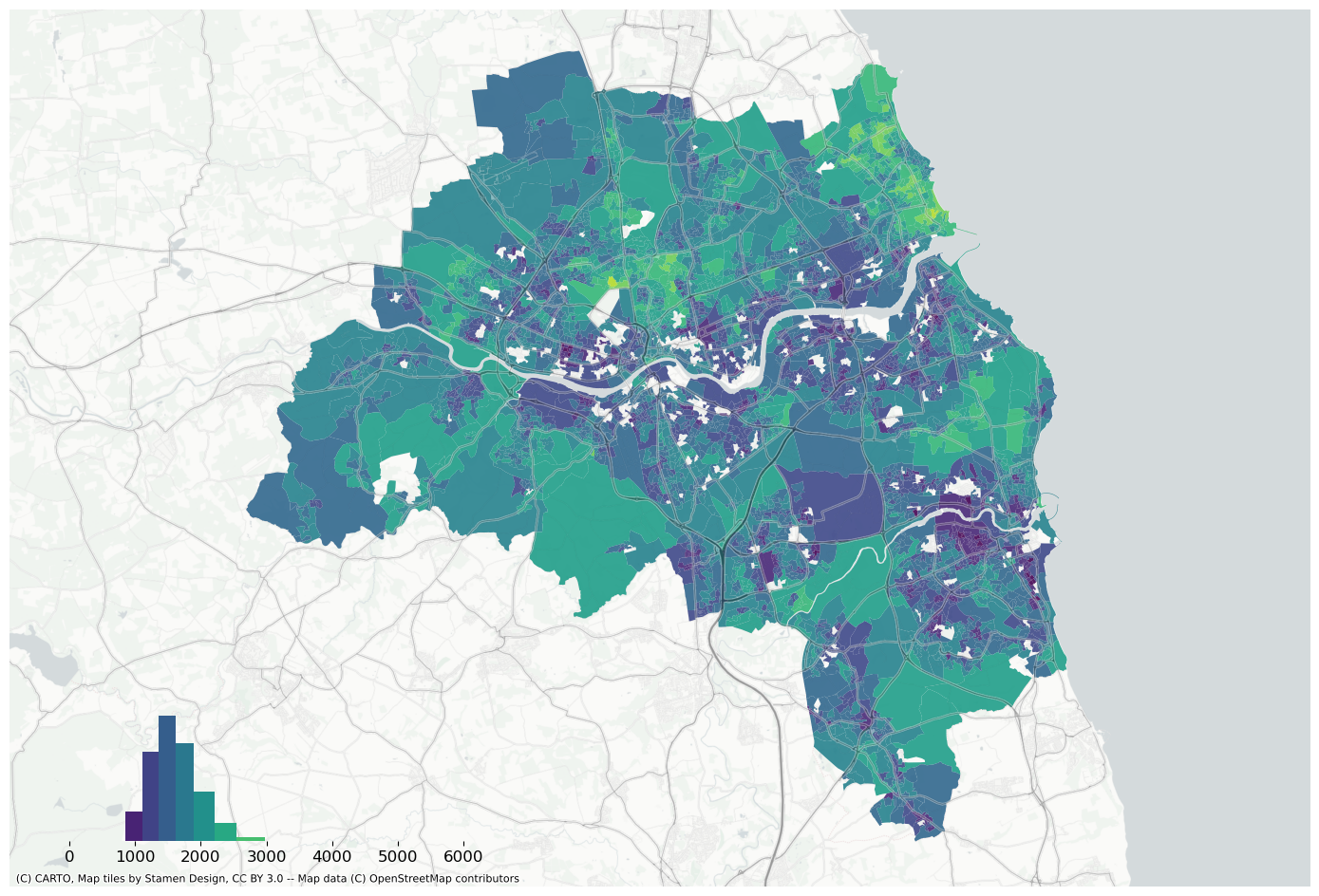
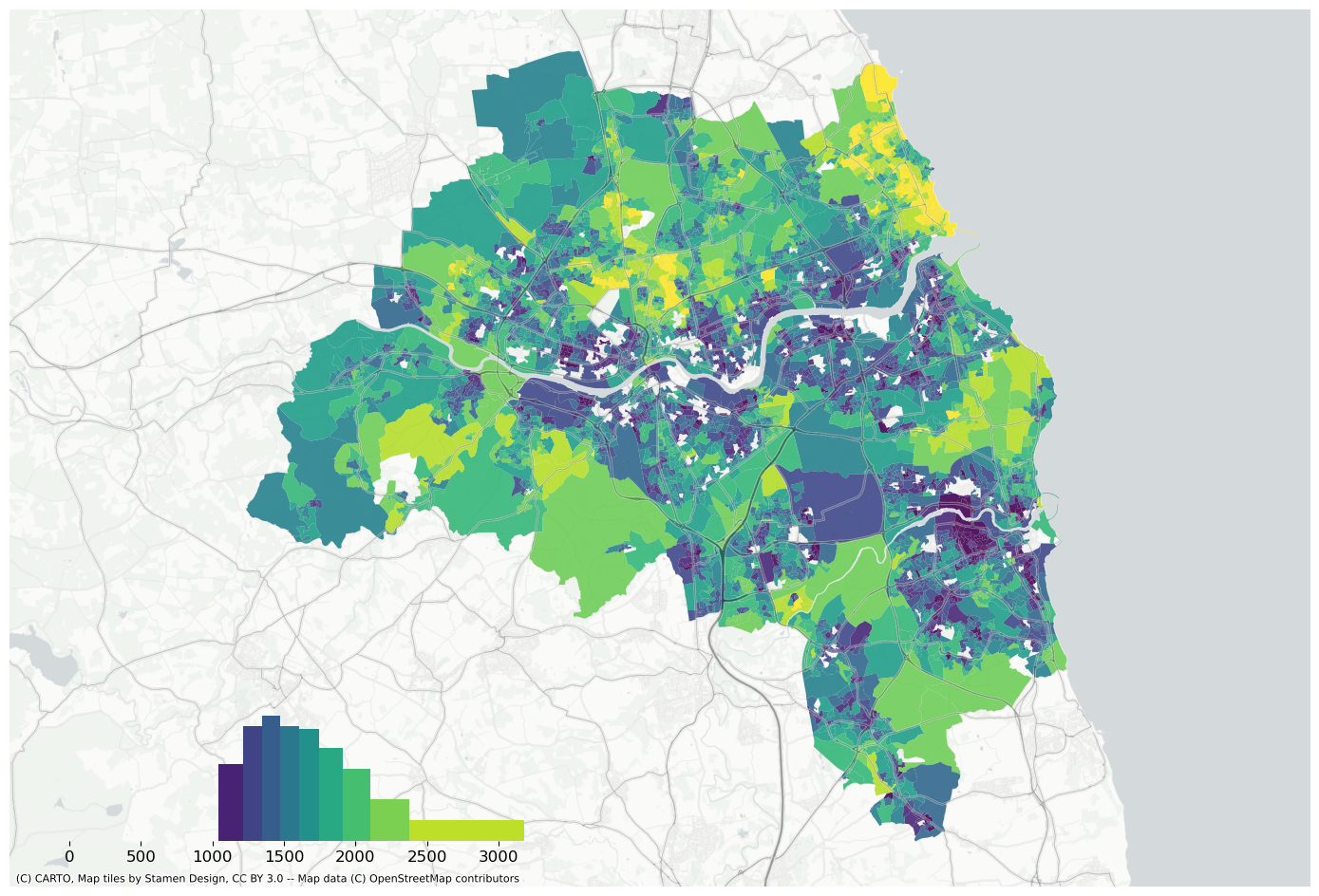
Plot prediction using the same bins as real values.
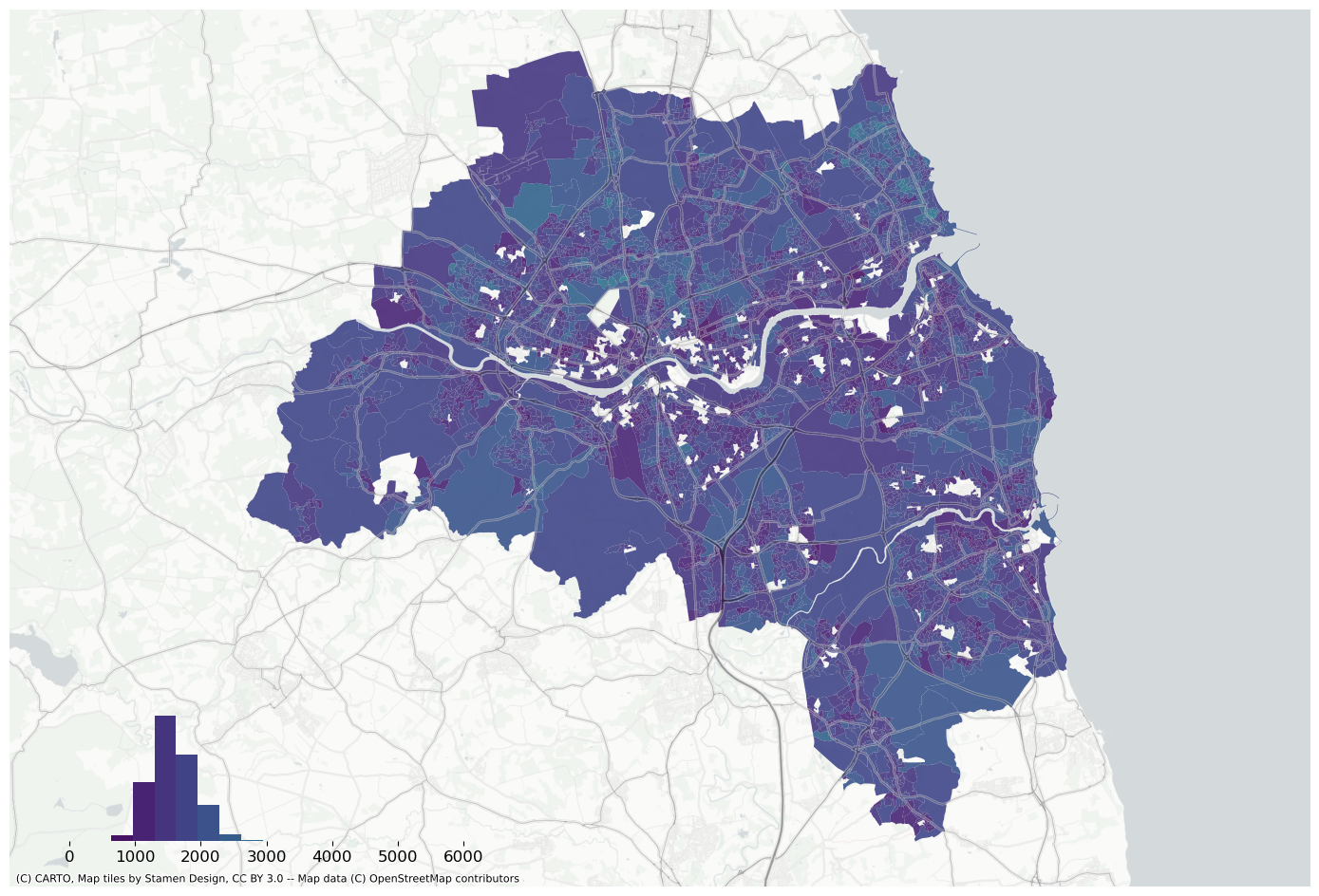
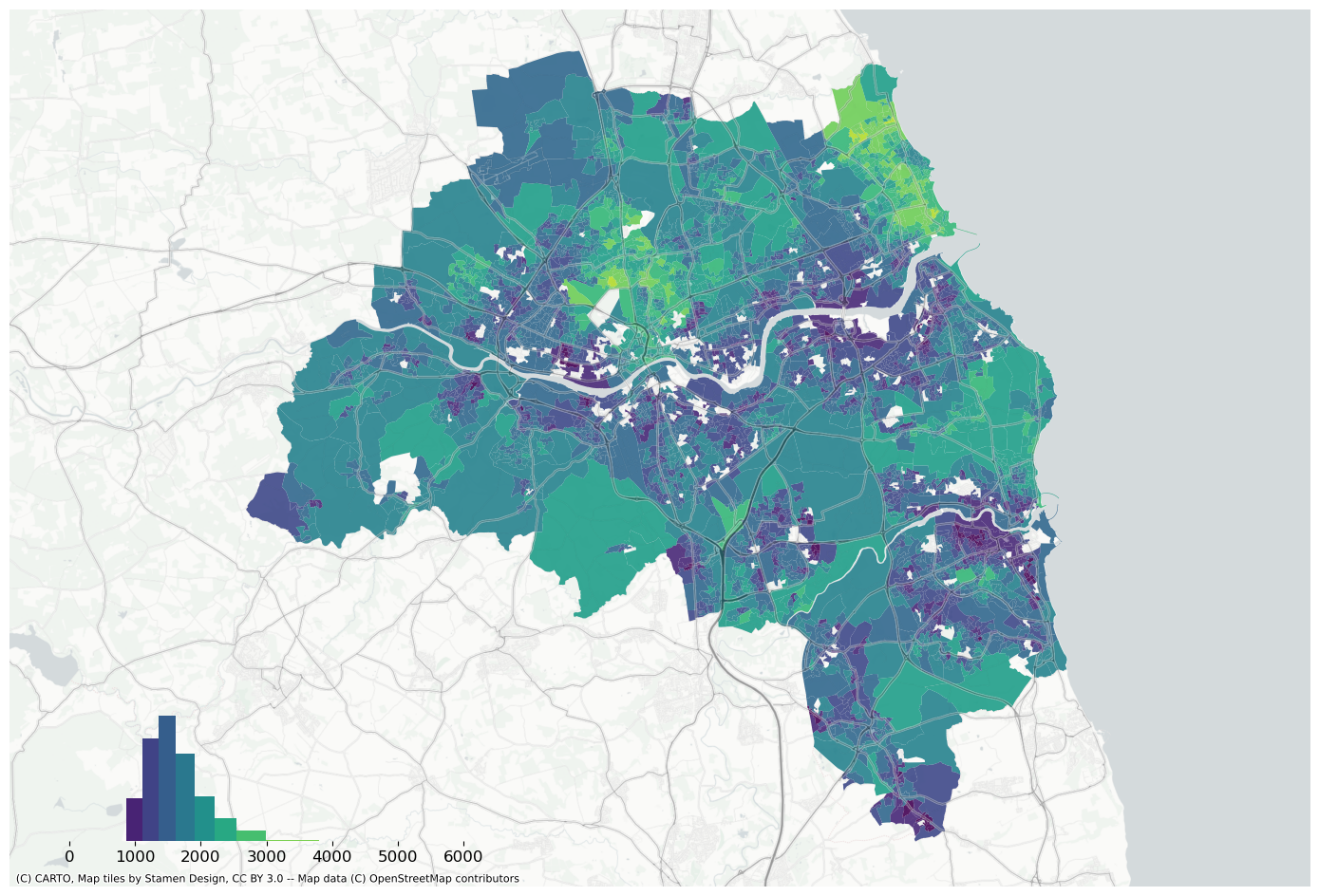
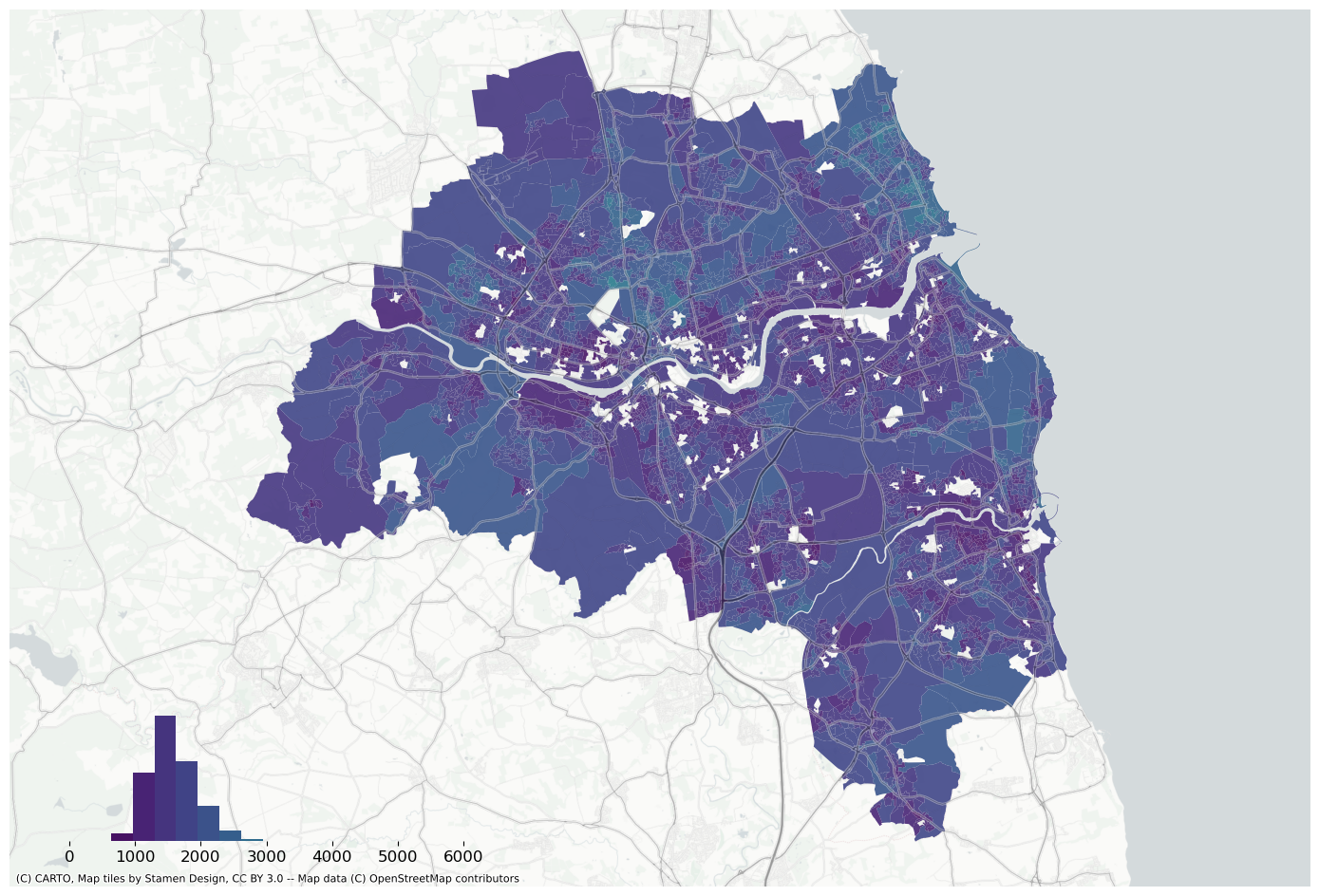
f, ax = plt.subplots(figsize=(18, 12))extent.plot(ax=ax, alpha=0)bins = mapclassify.NaturalBreaks(data["house_price_index"].dropna().values, k=10).binsdata.assign(pred=pred_lag).to_crs(3857).plot("pred", scheme="userdefined", classification_kwds={"bins": bins}, ax=ax, alpha=0.9, cmap="viridis",)legendgram( f, ax, pred_lag, bins, pal=palmpl.Viridis_10, legend_size=(0.35, 0.15), # legend size in fractions of the axis loc="lower left", # matplotlib-style legend locations clip=(0, data["house_price_index"].max(), ), # clip the displayed range of the histogram)ax.set_axis_off()contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels, attribution="")contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors",)# plt.savefig(f"{data_folder}/outputs/figures/air_quality_index.png", dpi=150, bbox_inches="tight")
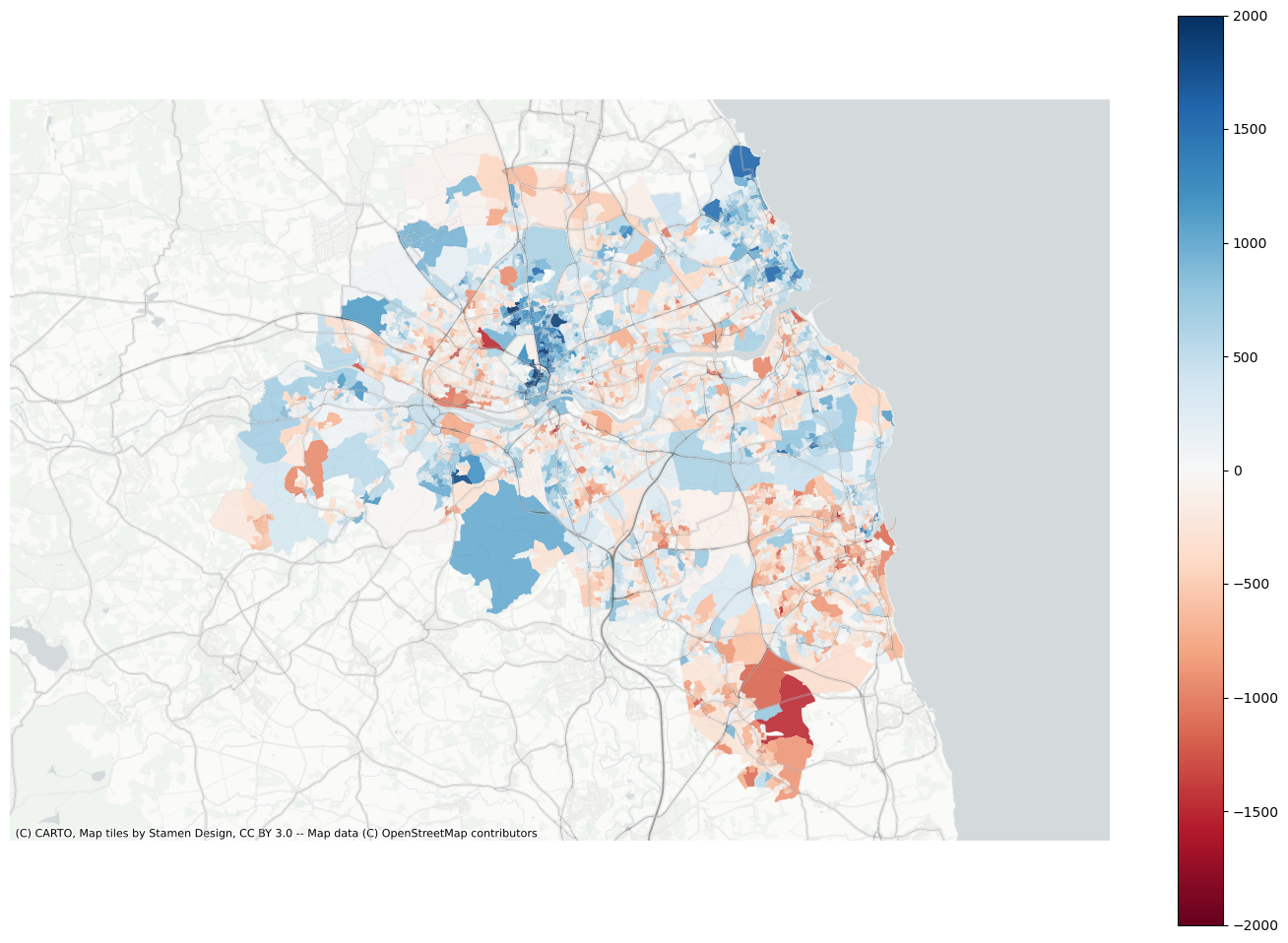
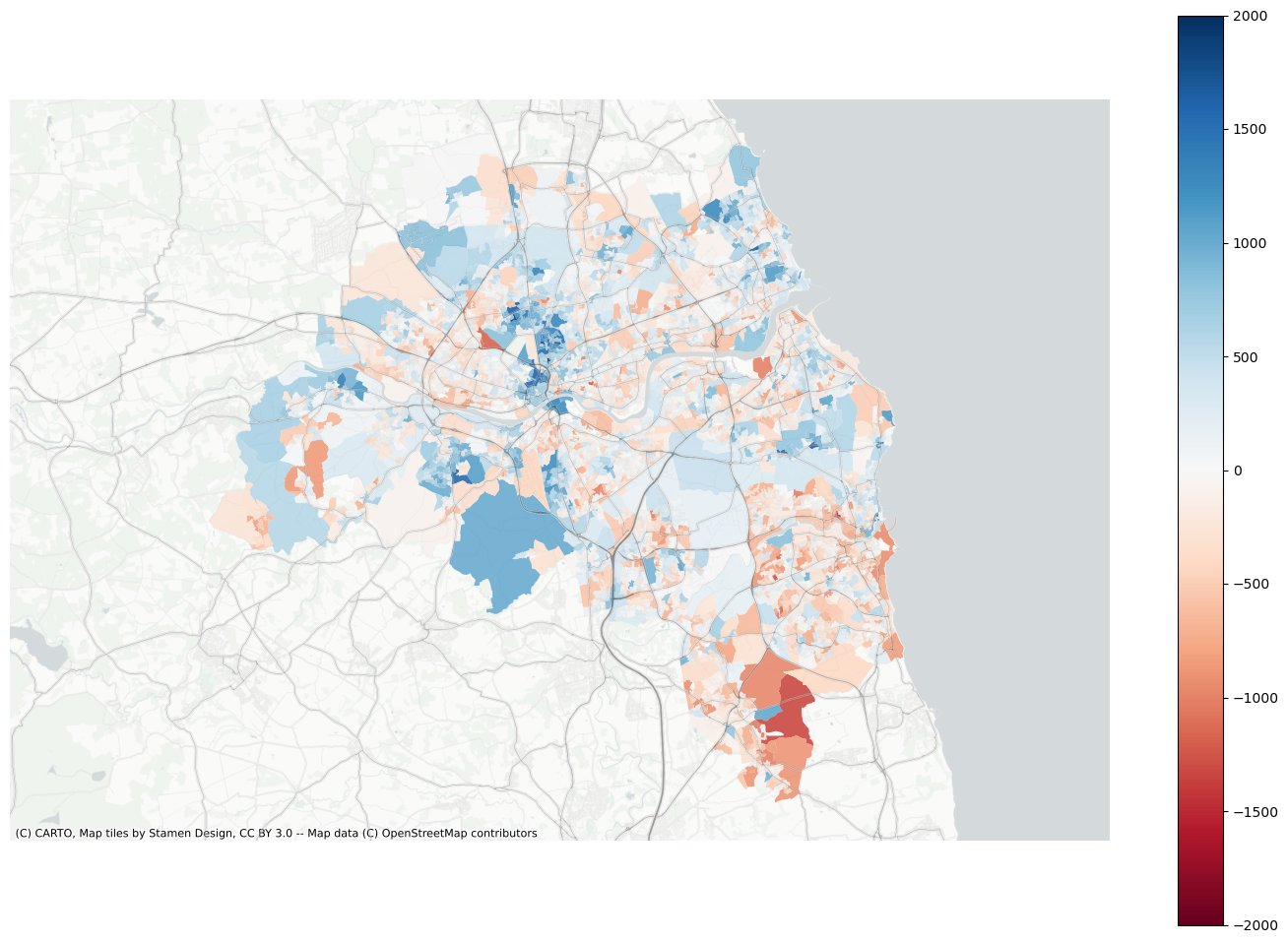
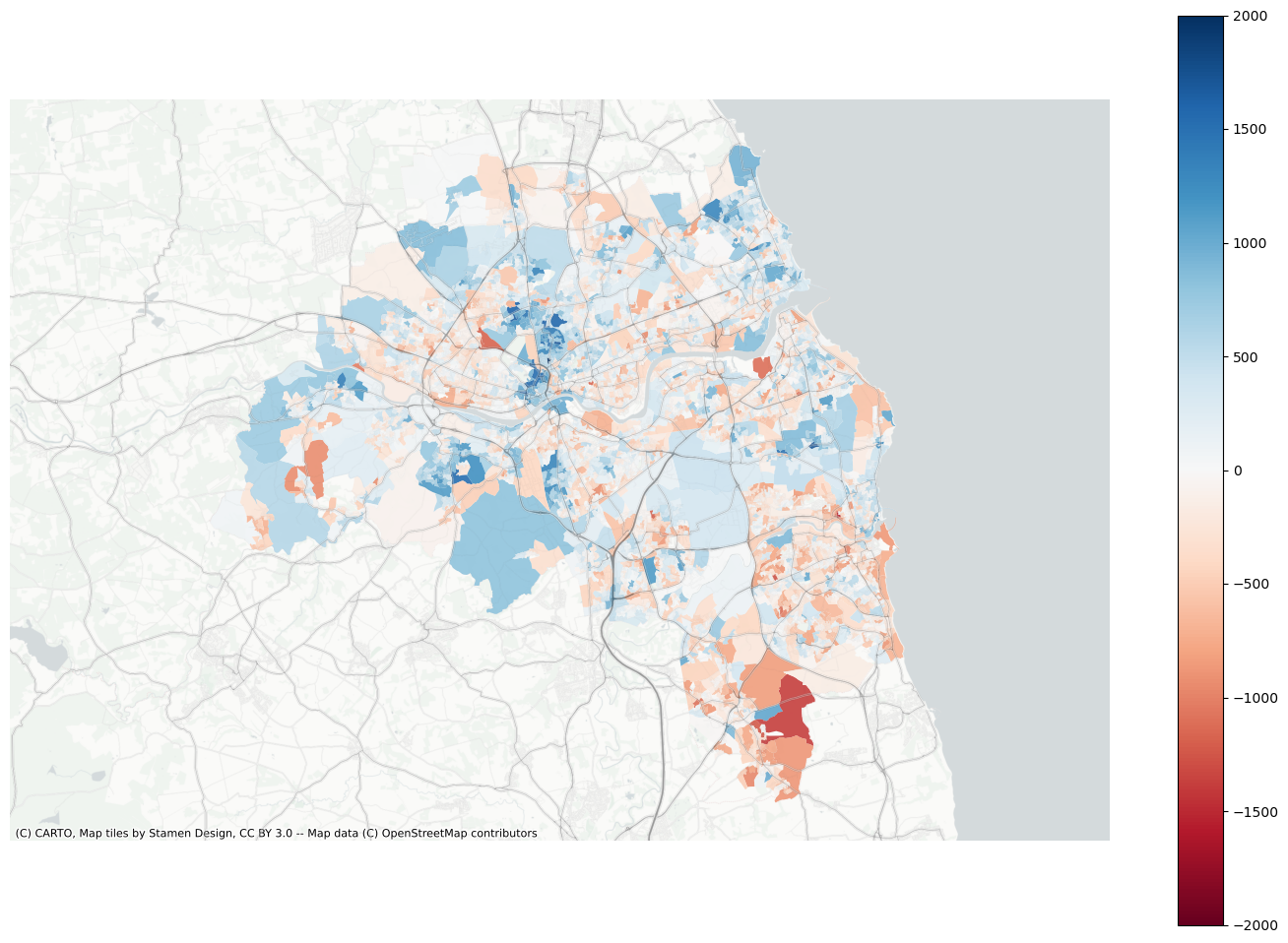
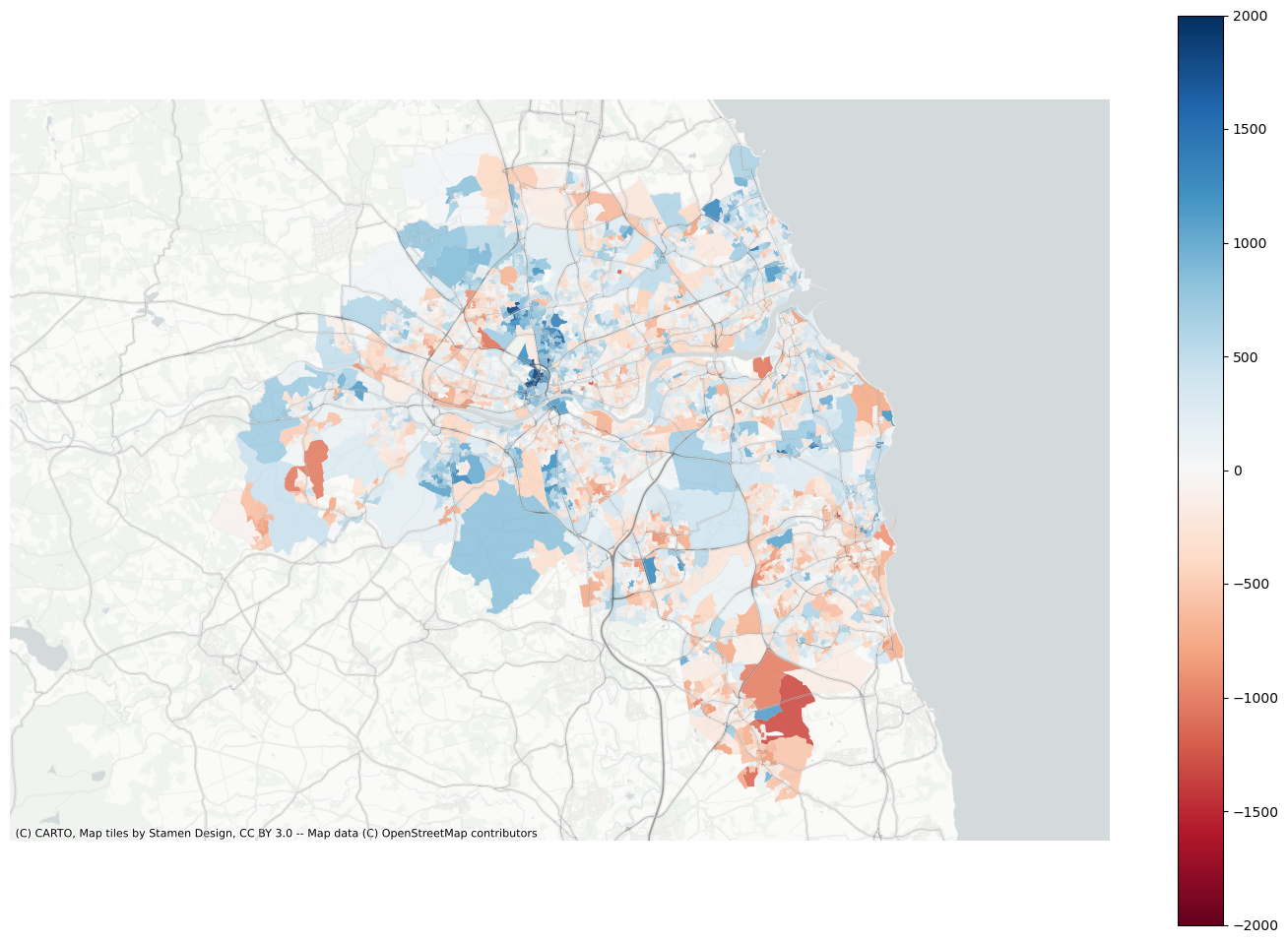
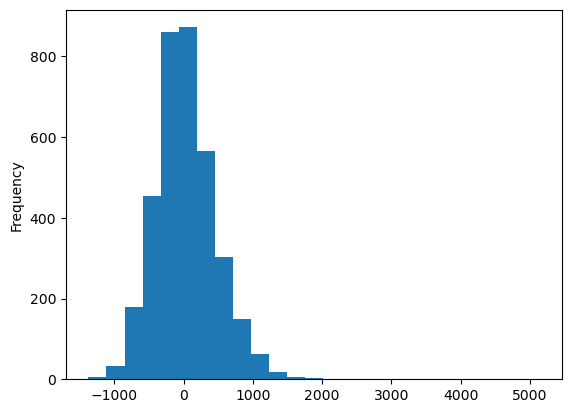
Plot residuals
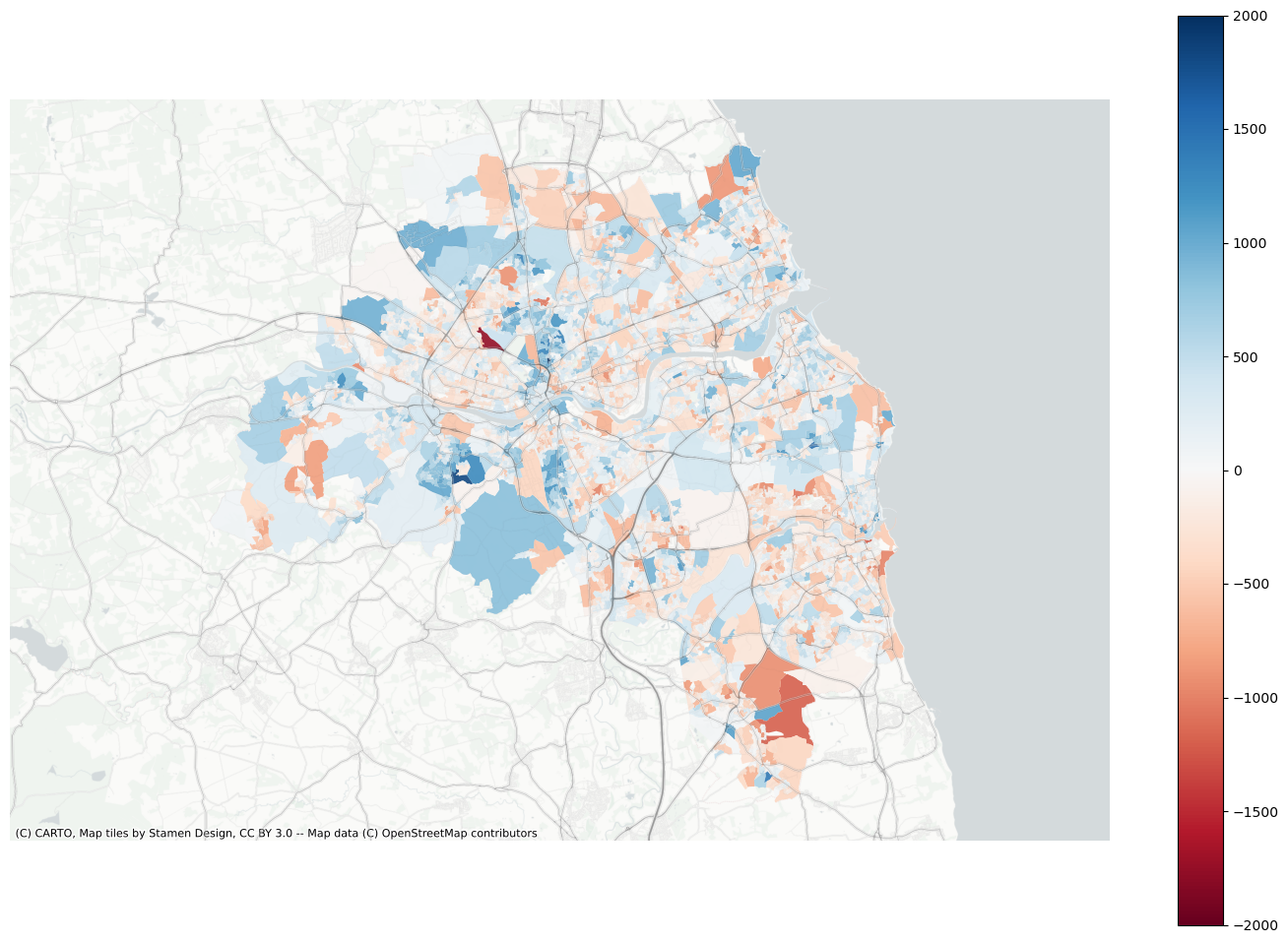
f, ax = plt.subplots(figsize=(18, 12))extent.plot(ax=ax, alpha=0)data.assign(res=residuals_lag).to_crs(3857).plot("res", ax=ax, alpha=0.9, cmap="RdBu", vmin=-2000, vmax=2000, legend=True)ax.set_axis_off()contextily.add_basemap( ax=ax, source=contextily.providers.CartoDB.PositronNoLabels, attribution="")contextily.add_basemap( ax=ax, source=contextily.providers.Stamen.TonerLines, alpha=0.4, attribution="(C) CARTO, Map tiles by Stamen Design, CC BY 3.0 -- Map data (C) OpenStreetMap contributors",)# plt.savefig(f"{data_folder}/outputs/figures/air_quality_index.png", dpi=150, bbox_inches="tight")
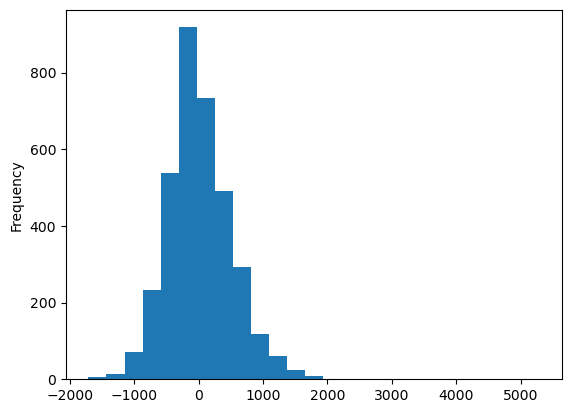
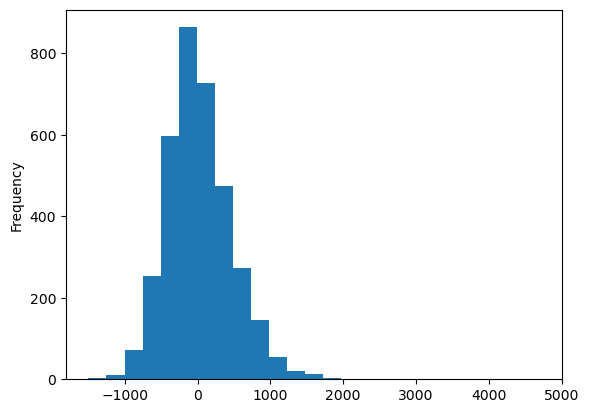
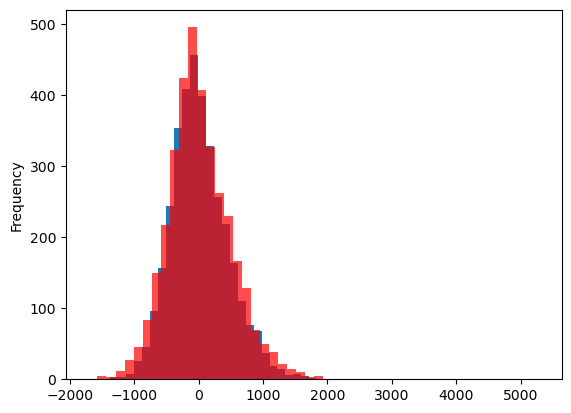
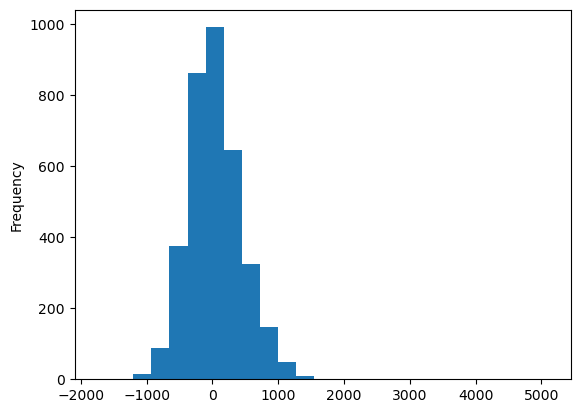
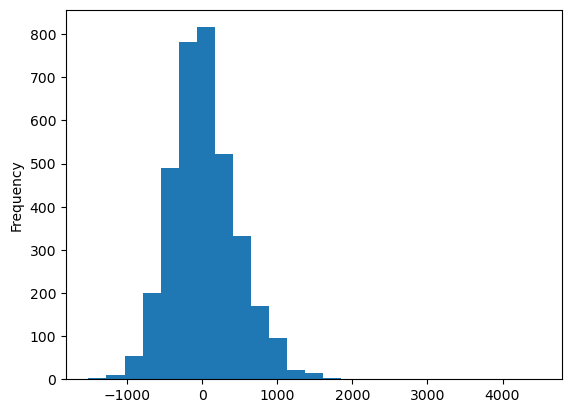
residuals_lag.plot.hist(bins=25)
L.2 Include accessibilities
We can try to include green space and jobs accessibility, as those are likely to affect the house price. We create a lagged model with these two variables on top of explanatory variables.
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 3 disconnected components.
warnings.warn(message)
for col in exvars.columns.copy(): exvars[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(queen, exvars[col])
exvars.head()
population_estimate
A, B, D, E. Agriculture, energy and water
C. Manufacturing
F. Construction
G, I. Distribution, hotels and restaurants
H, J. Transport and communication
K, L, M, N. Financial, real estate, professional and administrative activities
O,P,Q. Public administration, education and health
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
/Users/martin/mambaforge/envs/demoland/lib/python3.11/site-packages/libpysal/weights/weights.py:172: UserWarning: The weights matrix is not fully connected:
There are 3 disconnected components.
warnings.warn(message)
for col in exvars_latent.columns.copy(): exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial( queen, exvars_latent[col] )
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
/var/folders/2f/fhks6w_d0k556plcv3rfmshw0000gn/T/ipykernel_54818/186550642.py:2: PerformanceWarning: DataFrame is highly fragmented. This is usually the result of calling `frame.insert` many times, which has poor performance. Consider joining all columns at once using pd.concat(axis=1) instead. To get a de-fragmented frame, use `newframe = frame.copy()`
exvars_latent[f"{col}_lag"] = libpysal.weights.spatial_lag.lag_spatial(
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.